由下圖可知,我們所使用3x3的卷積核在2維圖像進行卷積(例如:3x3x3的卷積核)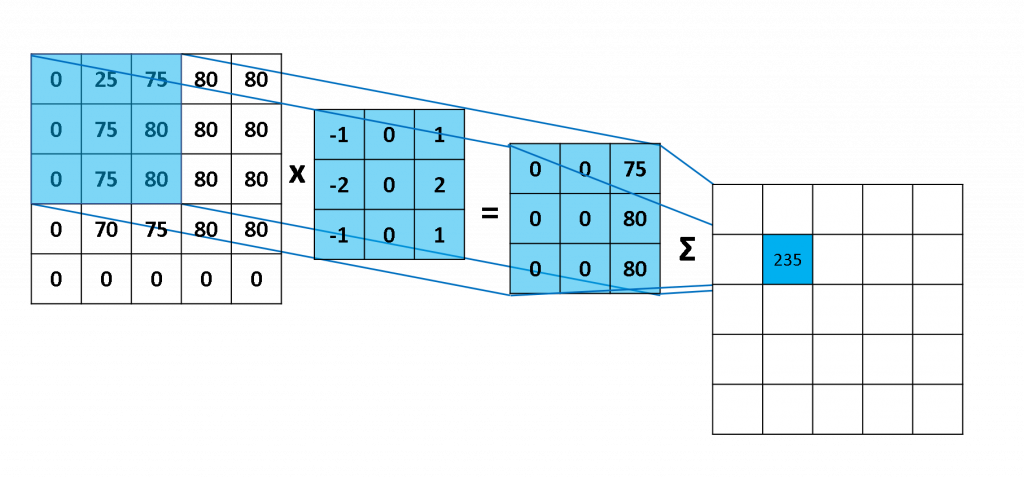
圖片來源:連結
在目前的應用中,我們可知道在視訊分類、動作辨識等多個領域發揮了模型本身的優勢。
3D CNN所使用的卷積核則為立方體,下圖所使用的卷積核則為3x3x3,使用3D CNN可以捕捉更多的訊息,若應用於視頻中,則會捕捉到空間、時間等資訊。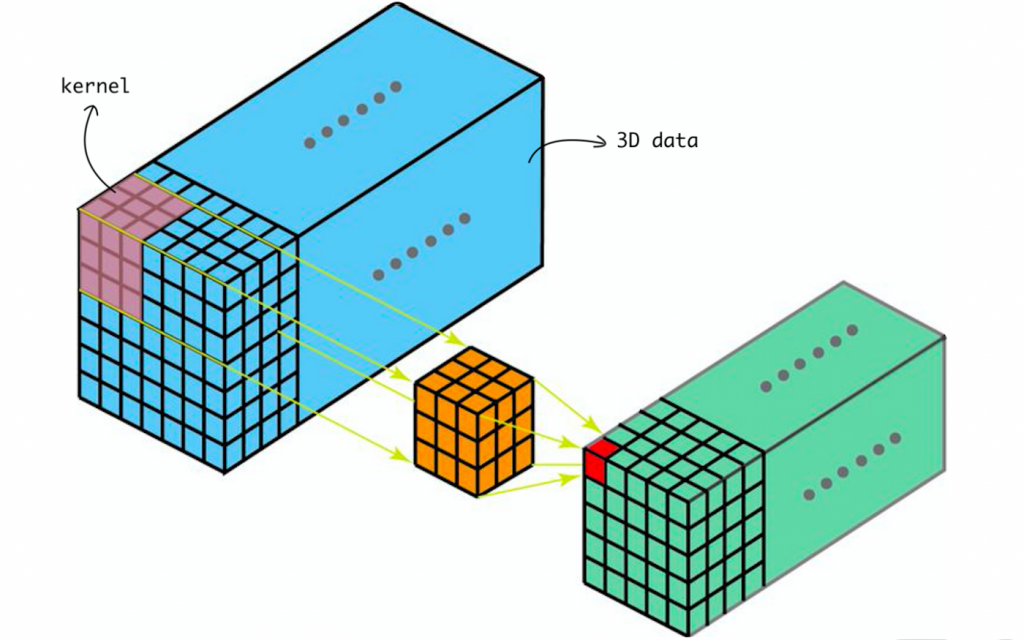
圖片來源:連結
由於腦波圖、肌電圖在紀錄時會獲得多個通道(Channel)的訊息,在多數研究中會使用3D CNN 來處理多通道的問題,可用下圖來作為代表,研究將多通道的訊號轉換成3D的圖片,因此使用3D CNN可以結合不同通道(Channel)的資訊。
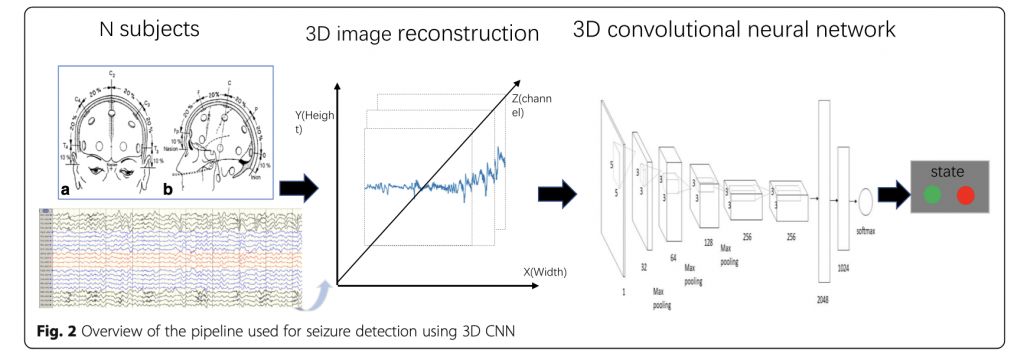
圖片來源:Wei, X., Zhou, L., Chen, Z., Zhang, L., & Zhou, Y. (2018). Automatic seizure detection using three-dimensional CNN based on multi-channel EEG. BMC medical informatics and decision making, 18(5), 71-80.
本次的實作,將接續上次的頻譜圖的實作,將每個不同通道的訊號轉換成頻譜圖,並利用3D CNN來結合64個通道的訊息來預測手勢的種類。
EMG_0 = pd.read_csv('./archive/0.csv',header=None)
EMG_1 = pd.read_csv('./archive/1.csv',header=None)
EMG_2 = pd.read_csv('./archive/2.csv',header=None)
EMG_3 = pd.read_csv('./archive/3.csv',header=None)
# 每個動作持續20秒,共紀錄6次
# 一筆資料代表40ms = 0.04 s
# 由於原始資料並沒有將每次紀錄切段,因此先根據資料集敘述進行資料切分
# 為了避免資料片段過少,因此決定嘗試以每5秒作為一片段,來作為嘗試,因此一個片段會包含125筆資料
segment = np.array([range(1,24)])
EMG_0 = EMG_0.iloc[0:2875,:]
EMG_0['segment'] = np.repeat(segment,[125])
EMG_1 = EMG_1.iloc[0:2875,:]
EMG_1['segment'] = np.repeat(segment,[125])
EMG_2 = EMG_2.iloc[0:2875,:]
EMG_2['segment'] = np.repeat(segment,[125])
EMG_3 = EMG_3.iloc[0:2875,:]
EMG_3['segment'] = np.repeat(segment,[125])
EMG_total = pd.concat([EMG_0, EMG_1, EMG_2, EMG_3])
EMG_total.columns = ["channel%02d" %i for i in range(1,65)]+['gesture','segment']
from scipy import signal
from scipy.fft import fftshift
import matplotlib.pyplot as plt
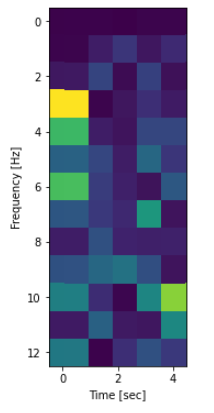
freq, times, spectrogram = signal.spectrogram(EMG_total.iloc[0:126,0], fs=25,nperseg=25) ### spectrogram = dim(13,5)
plt.figure(figsize = (5,14))
plt.pcolormesh(times, freq, spectrogram)
plt.imshow(spectrogram)
plt.ylabel('Frequency [Hz]')
plt.xlabel('Time [sec]')
plt.show()
### create 4D CNN
gesture = []
segment_store = []
segment_index = [ i for i in range(0,11500,125)]
for segment in range(0,91):
temp_store = []
for channel in range(0,64):
freq, times, spectrogram = signal.spectrogram(EMG_total.iloc[segment_index[segement]:segment_index[segement+1],channel], fs=25,nperseg=25)
if channel == 0:
temp_store = spectrogram
else:
temp_store = np.dstack([temp_store,spectrogram])
segment_store.append(temp_store)
gesture.append(EMG_total.iloc[segment_index[segment],64])
data = np.stack(segment_store,axis=-1) ### (13, 5, 64, 91)
data = np.transpose(data, (3,0,1,2))
data.shape ### (91, 13, 5, 64)
gesture = np.array(gesture) ### (91,)
## 切分訓練測試集
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(data, gesture, test_size=0.2)
x_train.shape # (72, 13, 5, 64)
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
## 建立模型
def get_model(width=13, height=5, depth=64):
"""Build a 3D convolutional neural network model."""
inputs = keras.Input((width, height, depth, 1))
x = layers.Conv3D(filters=32, kernel_size=3, activation="relu",padding="same")(inputs)
x = layers.MaxPool3D(pool_size=2)(x)
x = layers.BatchNormalization()(x)
x = layers.Conv3D(filters=64, kernel_size=3, activation="relu",padding="same")(x)
x = layers.MaxPool3D(pool_size=2)(x)
x = layers.BatchNormalization()(x)
x = layers.GlobalAveragePooling3D()(x)
x = layers.Dense(units=128, activation="relu")(x)
x = layers.Dropout(0.3)(x)
outputs = layers.Dense(units=4, activation="softmax")(x)
# Define the model.
model = keras.Model(inputs, outputs,)
return model
# Build model.
model = get_model(width=13, height=5, depth=64)
model.summary()
model.compile(loss = "sparse_categorical_crossentropy",
optimizer = "adam",
metrics = ["accuracy"])

model_fit = model.fit(x_train, y_train, epochs = 25)
result = model.predict(x_test)
result = np.argmax(result , axis = 1)

根據結果,模型尚未達到較好的結果,因此仍有更多加強的部分,可使用更加複雜的結構等方法來改善。


 iThome鐵人賽
iThome鐵人賽